During the PyData2019 conference, I took part in the Democracy Hackathon, hosted by Newspeak House (The London College of Political Technologists), which took the format of a Kaggle-style machine learning competition for predicting the turnout of UK general elections. SixFifty has been working hard to source and produce model-ready datasets for solving this problem.
My team was given a Jupyter notebook that applied a linear regression model on a dataset of the 2010 and 2015 General Election results, which predicted the voter turnout for the 2017 General Election with a mean error of 4%.

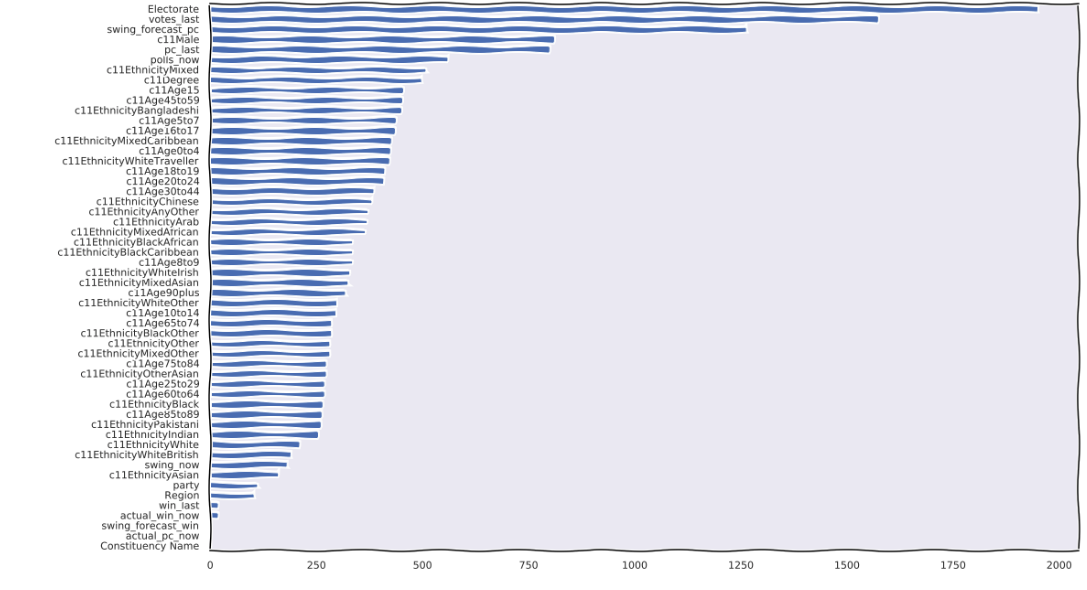
Our aim was to find a way to improve this in 2.5 hours. To do this, we applied a Gradient Boosting Decision Tree algorithm to this problem. This hackathon taught us the importance of domain knowledge – a big part of our success came from locating, cleaning and introducing data from the 2011 Census. The features that we thought play a significant role in determining voter turnout included people’s gender, attainment of a higher education degree, ethnicity and age (including ages of those below the voting age, therefore having a family/children plays a role).
Using this, we reduced the mean error to just shy of 3%, and as a result won the competition. Below is a plot with the features from the data that played the biggest role in descending order.